今天一樣繼續學習~今天要學習的主題是CNN architectures,參考資料為Stanford University課程,Fei Fei Li & Justin Johnson & Serena Yeung 開設.這個大名鼎鼎的課程應該大家都看過.
LeNet-5: 應用在手寫數字辨識.
Conv filters 使用5x5 stride = 1
subsampling(Pooling) 使用2x2 stride = 2
Conv -> Pool -> Conv -> Pool -> Fc -> Fc
圖: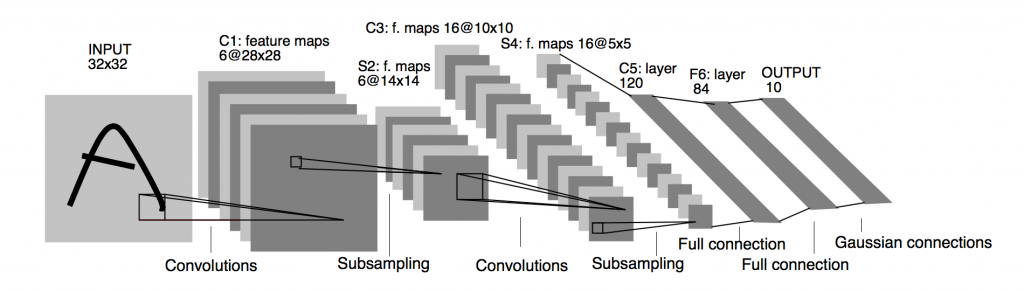
AlexNet:在2012擊敗所有非深度學習模型贏得影像分類(image classification)比賽,開啟了deep network研究浪潮.
架構: conv maxpool norm conv maxpool norm conv conv conv maxpool fc fc fc
可以看出跟LeNet差不多架構只是比較多層.
input = 227x227x3 images
第一層conv使用11x11 96個 filters at stride 4
Output volumn size ? 55x55x96 55因為:(227-11)/4+1 = 55
parameters = 11x11x3x96 個
第二層pool 使用3x3 filters at stride 2
output volumn size ? (55-3)/2+1=27 27x27x96
parameters = 0 !
Full architecture:
227x227x3 Input
55x55x96 CONV1 96 11x11,stride=4,pad0
27x27x96 MAXPOOL1 3x3,stride=2
27x27x96 NORM1 Normalization
27x27x256 CONV2 256 5x5,stride=1,pad2
13x13x256 MAXPOOL2 3x3,stride=2
13x13x256 NORM2 Normalization
13x13x384 CONV3 384 3x3,stride=1,pad1
13x13x384 CONV4 384 3x3,stride=1,pad1
13x13x256 CONV5 256 3x3,stride=1,pad1
6x6x256 MAXPOOL3 3x3,stride=2
4096 FC
4096 FC
1000 FC
圖: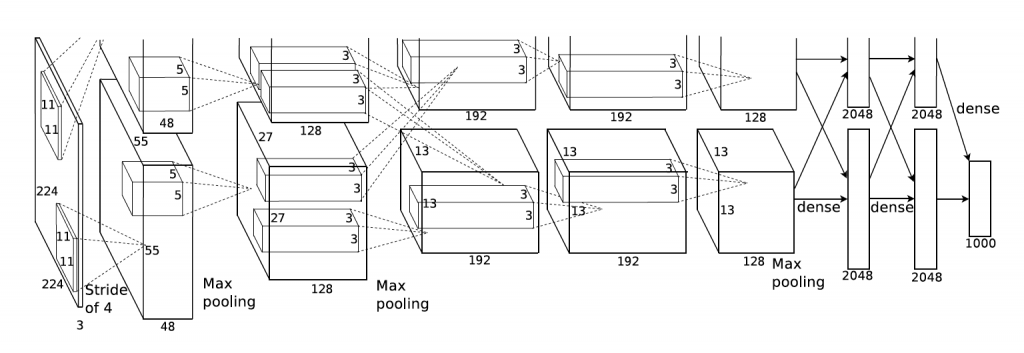
Details:
2014: GoogleNet 和 VGG出現將比賽成績向前推進一大步.
VGG: much deeper network, much smaller filter
Alex(8 layers) -> VGG(16layers)
Only 3x3 conv at stride=1, pad=1 and 2x2 maxpool at stride=2
Why use smaller filter? ->
圖: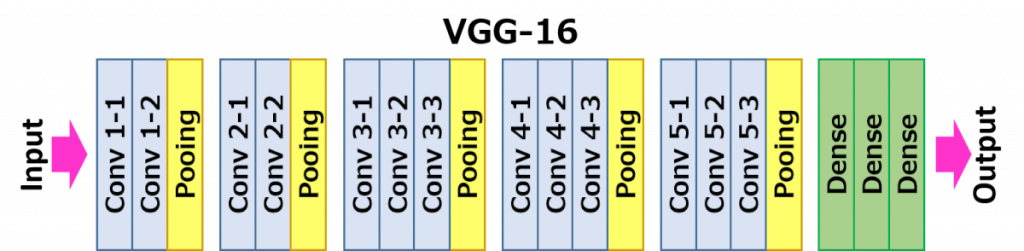
由上圖所知由於層數增加參數變多->computation complexity
Details:
明天接著學習GoogLeNet

